
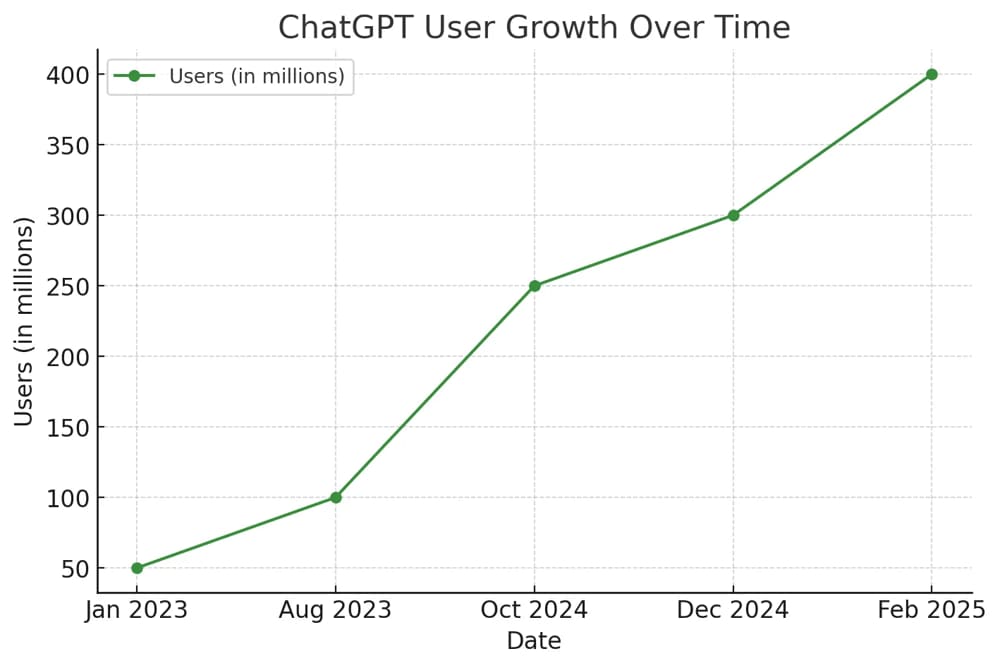
近年来,人工智能(AI)技术飞速发展,尤其是在自然语言处理(NLP)领域,ChatGPT成为人们关注的焦点。从ChatGPT 3到最新的ChatGPT 4.0,每一次迭代都带来了巨大的技术飞跃。那么,ChatGPT 4.0是如何被训练出来的?它的背后到底蕴藏着怎样的工作原理?本篇文章将全面解析ChatGPT 4.0的训练流程、核心技术和其背后的深度学习机制。

一、ChatGPT 4.0概述
ChatGPT 4.0是由OpenAI推出的一种先进的大语言模型(Large Language Model, 简称LLM),它的核心基于Transformer架构,并在海量文本数据上进行了训练。相比于前代模型,ChatGPT 4.0拥有更强的语言理解与生成能力,更高的准确性,更少的偏见,同时对图像输入的处理能力也得到了提升。
ChatGPT账号价格表
二、ChatGPT的训练目标
训练ChatGPT 4.0的目标主要有以下几点:
-
语言理解能力增强:提升对上下文语境的把握能力。
-
文本生成质量优化:生成更自然、连贯、语法正确的文本。
-
减少不良输出:通过训练约束模型减少生成有害或不当内容的概率。
-
多模态能力提升:整合语言与视觉数据,实现跨模态的理解与生成。
-
可调节性与安全性:提高对人类指令的响应性,并在安全框架下生成内容。
三、ChatGPT 4.0训练的核心阶段
ChatGPT 4.0的训练可划分为三个主要阶段:
1. 预训练(Pretraining)
这是整个训练流程中最关键的步骤,主要目标是使模型掌握语言的基本规律与结构。
– 数据来源
预训练使用的大规模语料数据来自网络,包括网页内容、新闻、书籍、百科、论坛等。OpenAI通过筛选机制去除低质量或敏感数据,确保数据的广泛性和中立性。
– 训练目标
采用自回归语言建模(autoregressive language modeling),即给定前文预测下一个词。例如:
– 技术基础
预训练阶段使用的是Transformer架构,通过多个编码器-解码器层,模型逐渐学习文本之间的上下文联系和逻辑结构。
2. 微调(Fine-tuning)
预训练完成后,模型已具备语言基础能力,但仍不够实用。因此,需要通过有监督微调(Supervised Fine-Tuning, SFT)进一步优化。
– 监督数据
这一步骤中,开发者会设计问答对话数据,或者人工标注的数据样本,如:
-
问题:“什么是黑洞?”
-
答案:“黑洞是一种密度极高的天体,其引力强大到连光也无法逃脱。”
模型在这些任务上进行训练,使其学会如何在特定语境下作出准确回答。
– 多轮对话训练
微调还包括多轮对话的训练,使模型能够理解上下文,持续进行相关回答,而不是“一问一答”。
3. 强化学习微调(RLHF:Reinforcement Learning with Human Feedback)
这是ChatGPT 4.0提升“智能感”与“自然度”的关键步骤。
– 人类反馈
开发者让多个版本的模型回答同一个问题,再由人类评审人员对这些回答打分,判断哪一条更好。
– 奖励模型(Reward Model)
根据人类打分数据,训练一个奖励模型,让模型学会偏向被人类认可的回答。
– 强化学习算法
在奖励模型的指导下,使用Proximal Policy Optimization(PPO)等强化学习方法进行迭代训练,让ChatGPT 4.0优化回答质量与风格。
四、ChatGPT 4.0背后的技术框架
1. Transformer架构
Transformer由Google在2017年提出,是一种基于“自注意力机制”(Self-Attention)的神经网络架构。它能有效捕捉文本中的远距离依赖关系。
2. 位置编码(Positional Encoding)
由于Transformer没有循环结构,为了捕捉词语的顺序,加入位置编码使模型能识别词语的相对位置。
3. 大规模并行训练
ChatGPT 4.0在成百上千个GPU甚至TPU集群上进行并行训练,使用模型并行(Model Parallelism)与数据并行(Data Parallelism)技术,加快训练速度。
4. 混合专家(Mixture of Experts)机制(部分猜测)
虽然OpenAI未公开具体细节,但有研究认为GPT-4可能引入了“稀疏激活”的专家模型结构,即在每次生成时,仅激活部分子模型,提高效率和表现力。
五、模型评估与测试
在训练完成后,OpenAI对ChatGPT 4.0进行了全面测试,包括:
-
知识问答能力
-
逻辑推理能力
-
多语言处理能力
-
编程任务能力
-
安全性与偏见测试
同时还邀请外部研究机构对模型进行“红队测试”(Red Teaming),模拟恶意用户行为,查找潜在风险。
六、ChatGPT 4.0的持续学习与更新机制
虽然ChatGPT在训练后不会“在线学习”用户对话,但OpenAI会定期收集用户反馈和使用数据,结合人工评审,不断优化模型:
-
修正错误
-
减少偏见
-
引入新知识
-
改进行为控制
通过周期性微调和模型版本更新,ChatGPT持续进化。
七、ChatGPT训练面临的挑战
1. 数据偏见与伦理问题
模型可能继承训练数据中的种族、性别、地域偏见。
2. 训练成本高昂
ChatGPT 4.0的训练消耗巨大,可能需要数百万美元的算力资源。
3. 可解释性差
当前的大语言模型仍是“黑盒”,很难解释其具体推理过程。
4. 信息过时
预训练数据有时间滞后性,模型可能缺乏最新知识。
八、未来展望:ChatGPT的演进方向
未来的大语言模型将继续向以下几个方向发展:
-
更强的多模态处理能力
-
更好的个性化与本地部署能力
-
更少的训练能耗与碳足迹
-
更高的安全性和控制性
同时,业界也在探索“检索增强生成”(RAG)与“小模型+大知识库”的方式,提升模型实时性与准确率。








暂无评论内容